Pipeline
AnthroTAP is an automated pseudo-labeling pipeline that distills the rich supervision signal in human motion videos into 2D point tracking data. By fitting SMPL models to detected people, projecting 3D mesh vertices onto the image plane, and resolving occlusions via ray-casting, it generates trajectories with accurate occlusion labels, entirely without manual annotation.
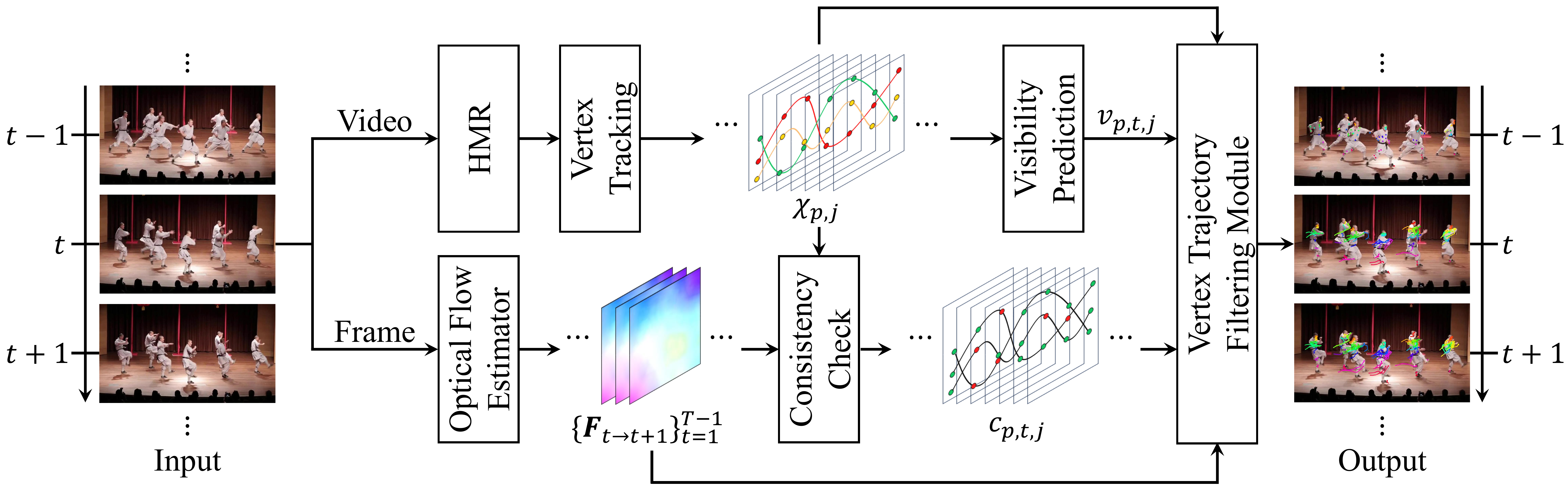 AnthroTAP pipeline: human mesh recovery and vertex projection form the core pseudo-labeling process, with ray-casting for occlusion modeling.
AnthroTAP pipeline: human mesh recovery and vertex projection form the core pseudo-labeling process, with ray-casting for occlusion modeling.
TokenHMR fits SMPL 3D body meshes to every person detected in each frame, producing a temporally consistent 3D mesh with Nv vertices per person.
3D mesh vertices are projected onto the 2D image plane using known camera parameters, forming initial pseudo-trajectories 𝒳p,j across frames.
A ray cast from the camera toward each 3D vertex is tested against all human mesh triangles. Points blocked before reaching the target are marked as occluded, resolving both self-occlusion and inter-person occlusion.
HMR-predicted displacements are compared against optical flow at each frame. Trajectory segments where the two diverge are discarded before training, catching occlusions from scene elements (e.g., furniture, background objects) outside the scope of the SMPL model.