DiTracker: Leveraging Video DiTs for Point Tracking
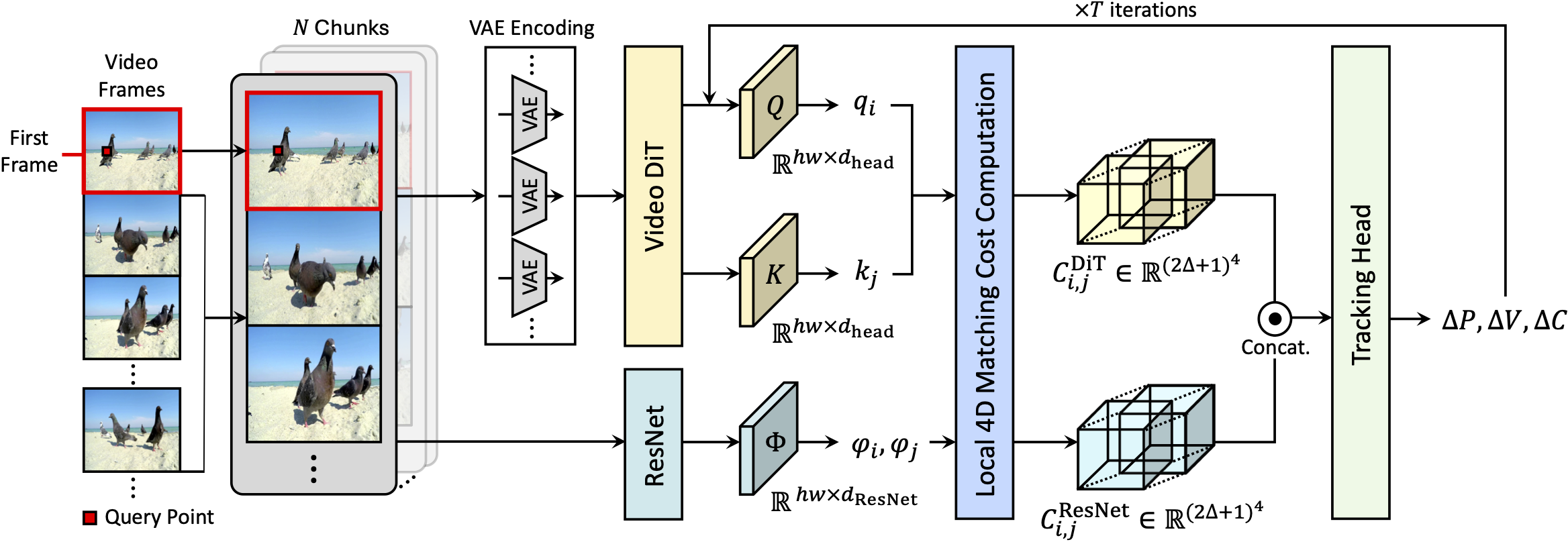
DiTracker turns a generative video DiT into a tracking backbone through three components. For long videos, frames are split into \( N \) temporal chunks with the global first frame prepended, encoded by a VAE, and processed by the video DiT to extract query features \( q_i \) and key features \( k_j \). (1) Query-key matching cost. We reuse the model's internal 3D attention to form the matching cost directly from its query and key projections, rather than learning a new one. (2) Cost fusion. The DiT matching cost is fused at the cost level with a higher-resolution ResNet cost to recover the fine spatial detail the low-resolution DiT features lack. (3) LoRA training. We adapt the frozen video DiT with lightweight LoRA so its generative features transfer to tracking. A tracking head then refines trajectories over \( T \) iterations, updating displacement \( \Delta P \), visibility \( \Delta V \), and confidence \( \Delta C \).