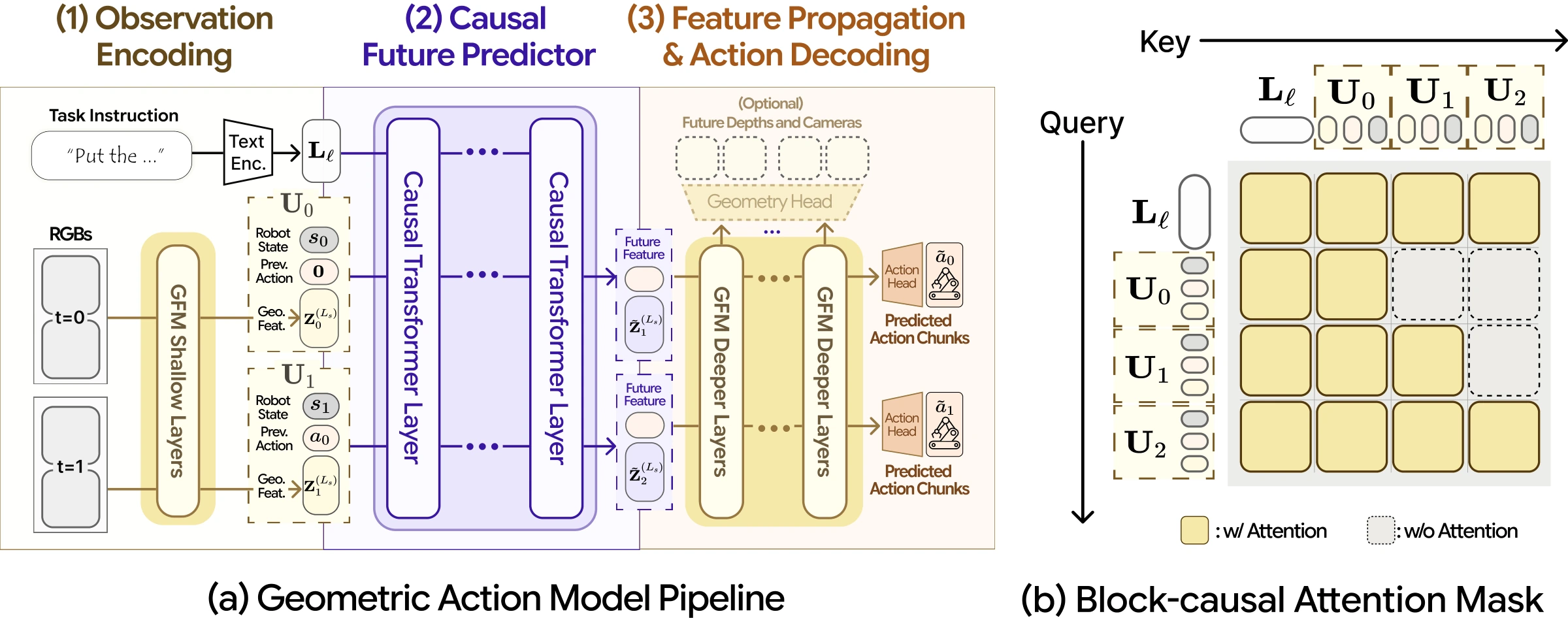
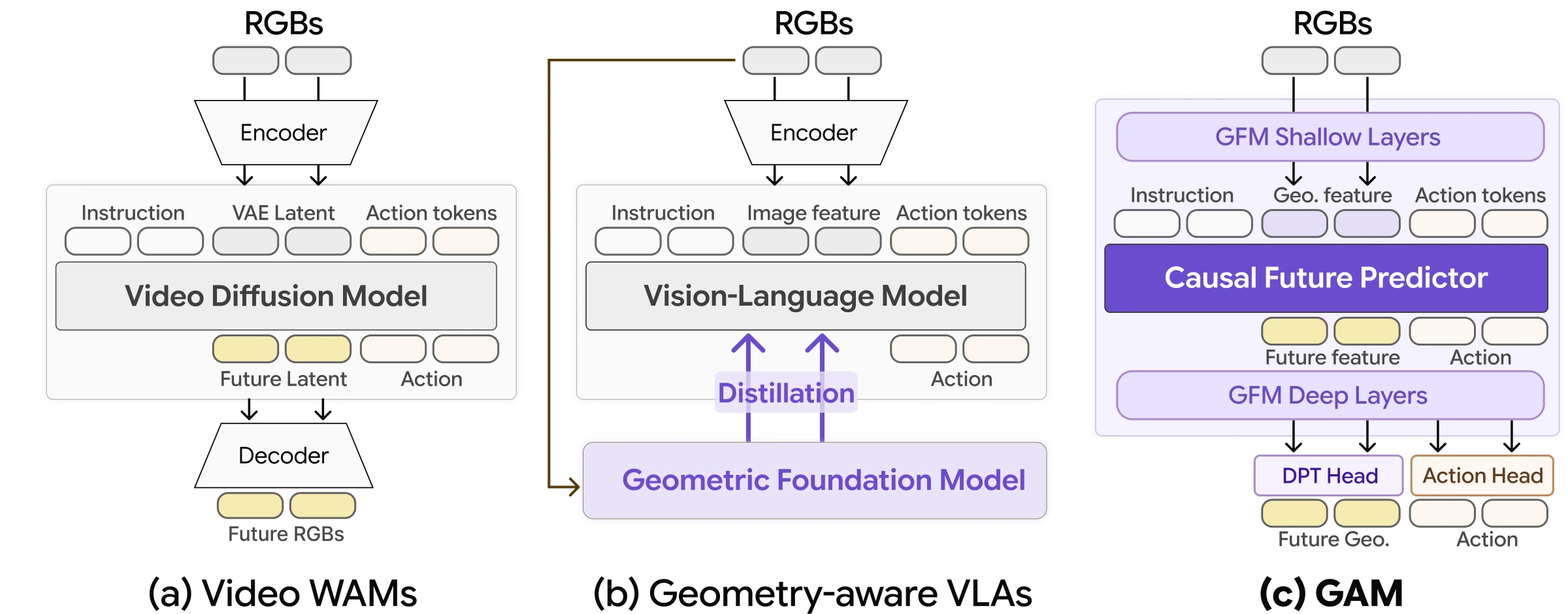
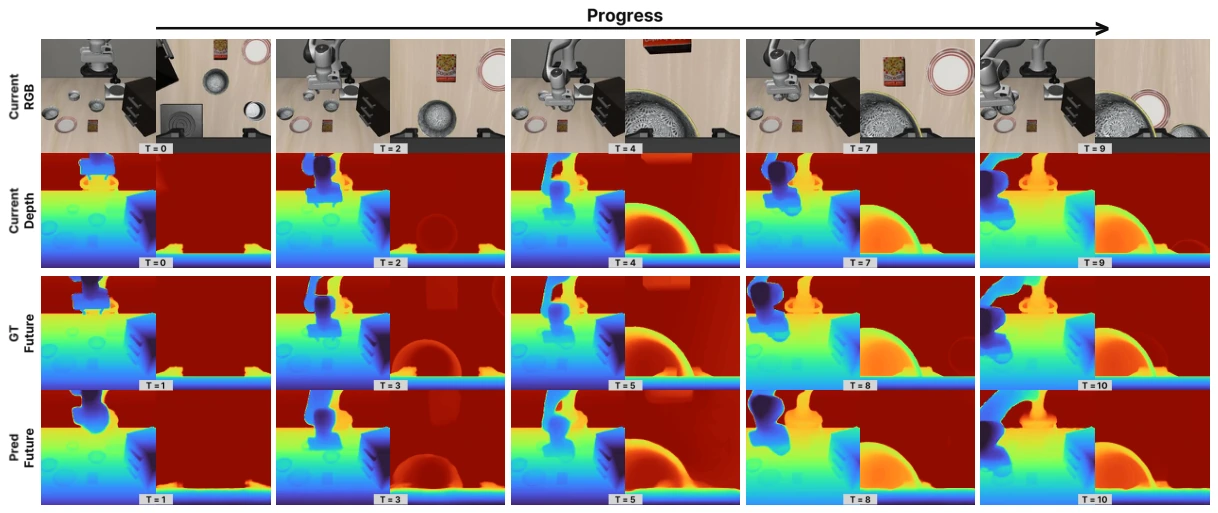
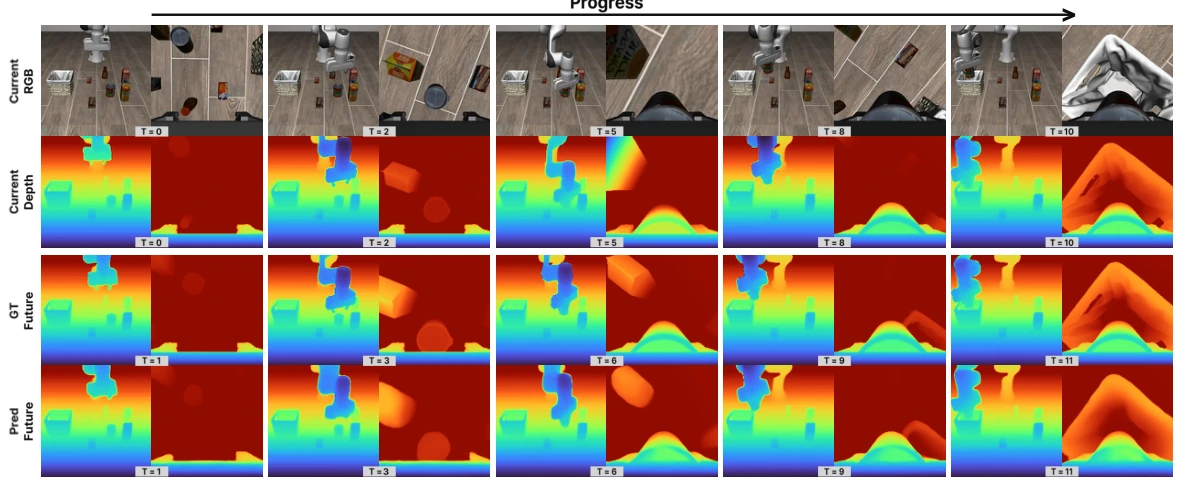
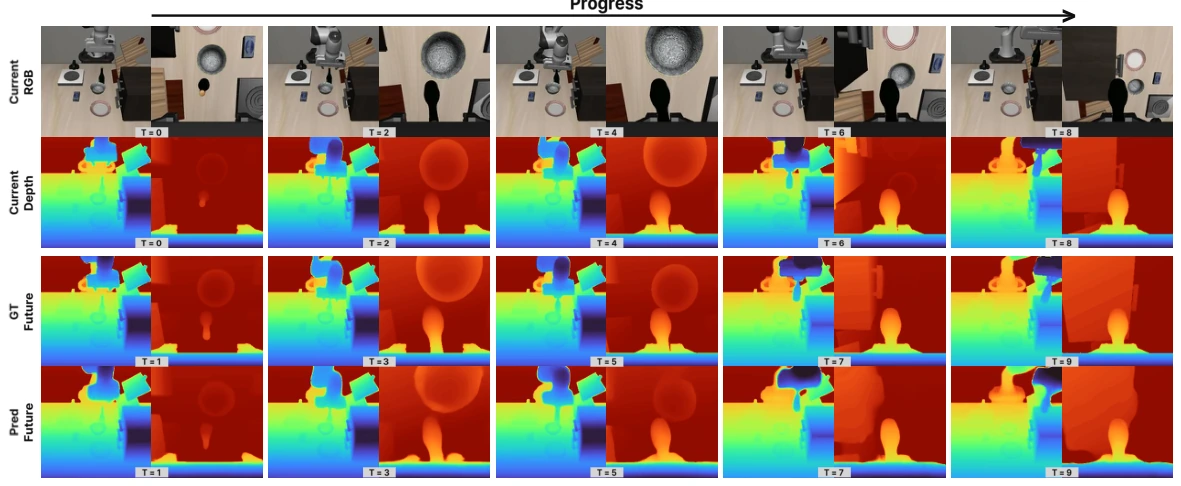
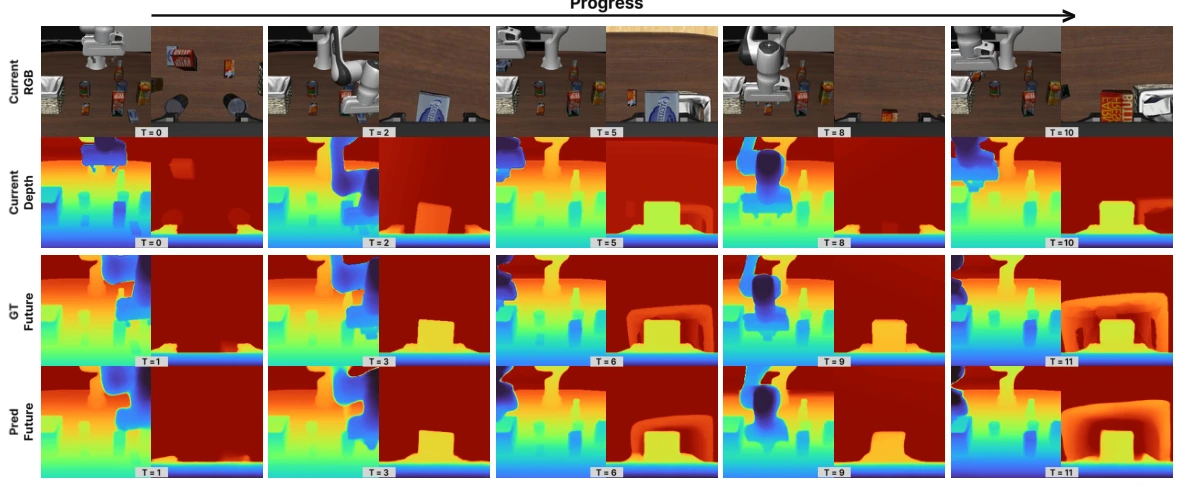
Geometric Action Model
for Robot Policy Learning
A language-conditioned manipulation policy that repurposes a pretrained geometric foundation model as one shared backbone for perception, future prediction, and action; more accurate, more robust, faster, and lighter than foundation-model-scale baselines.
1KAIST AI · 2ETH Zurich · 3ETH AI Center

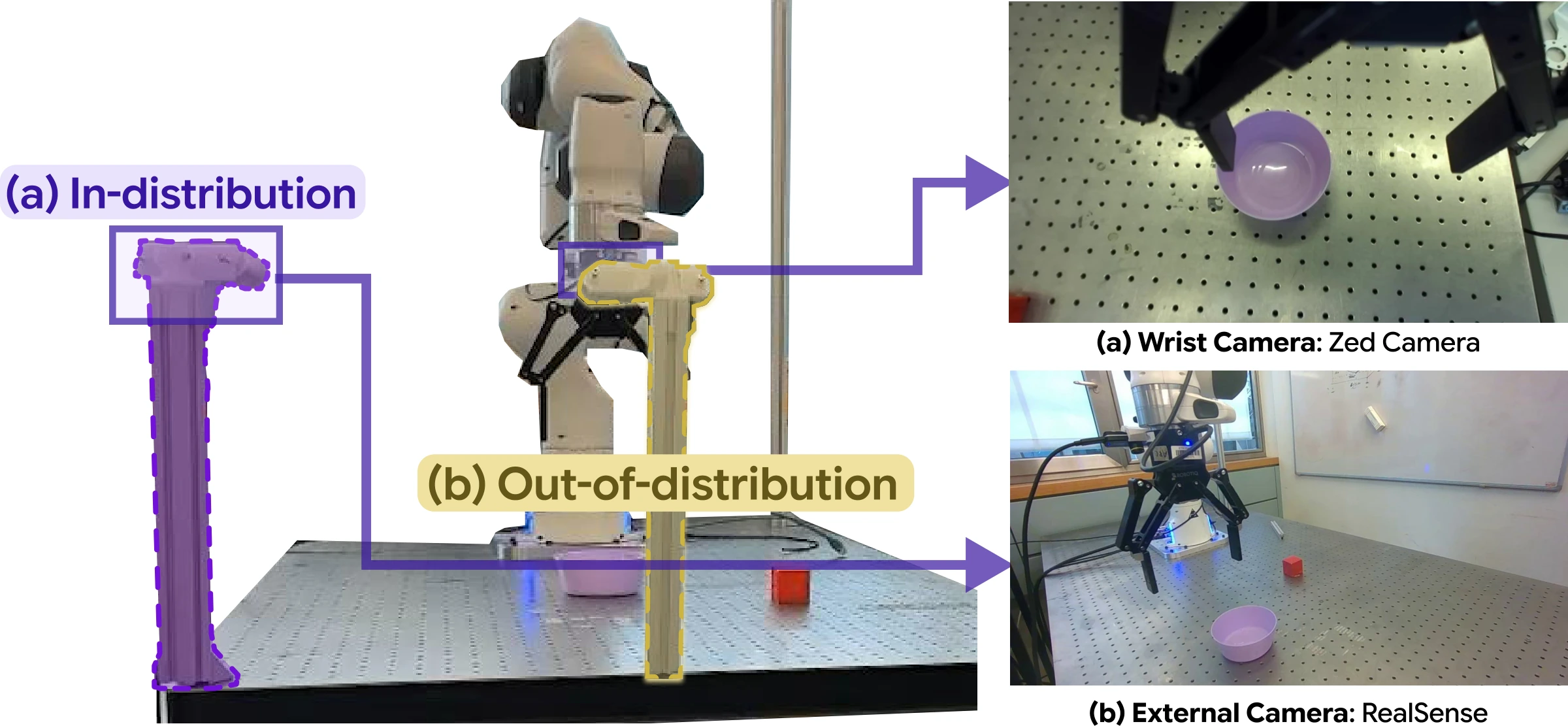
Real-robot comparison of GAM against π0.5 and Spatial Forcing across four manipulation tasks, in nominal (ID) and camera-perturbed out-of-distribution (OOD) settings.
85.5%
LIBERO-Plus success
best overall under perturbations
+9.7%p
Camera robustness
over the next-best baseline
6.9 ms
Inference latency
≈145 Hz · up to 55× faster
1.4B
Total parameters
vs 2–8.5B for baselines